
Statistical leverage of humans over LLMs
Everyone is talking about AI agents writing code, but almost no one is talking about the architectural limits that shape what they can and cannot invent, and where humans have the leverage
The context
I work in ZOHO, and I feel like everyone is stuck in the same question, is SaaS dead? given now agents can build a compiler by itself
Is SaaS industry dead?
Is coding dead?
Is Graphics Design or Content writing dead?
TL;DR: No. In fact, this is the Golden Age of the "Outlier."
The Autocomplete Illusion: A Simple Experiment
Before we dive into the math, I want you to experience exactly how an LLM "thinks." Take a look at this acronym and pause for a second to guess what it stands for:
IJWTBWMF
If you did, ask yourself: Why? There are millions of words in the English language. That acronym could stand for "In June We Take Big Water Melons Far" or "Iron Jellyfish Will Take Back West Mykonos Forever." Yet, your brain almost instantly converged on the answer (or something very similar)
You just experienced Context Filling.
Your brain didn't "read" the acronym in a vacuum. It acted as a prediction engine, scanning your training data (common human phrases, emotional context, sentence structures) and filling in the blanks with the statistically most probable sequence.
This is exactly how Large Language Models work.
The Mathematical Proof: Why AI Craves the Average
To understand why an AI struggles to build a novel architecture, we have to look at the math that powers it.
At its core, every Large Language Model is trying to solve one specific equation. It looks something like this:
P(w | context) = max [ Sum ( Probability of w given previous words ) ]
Don't let the symbols scare you.
- P(w) is the probability of the next word.
- context is everything you have typed so far.
- max [...] is the critical part.
The model is mathematically designed to maximize likelihood. In plain English, it asks: "What is the path most traveled?"
If 1,000 engineers on GitHub wrote a specific function one way, and 5 engineers wrote it a "brilliant new way," the statistical weight of the 1,000 will crush the 5. The model will converge to the Mean (the average).
It is a Regression to the Mean machine.
The industry is currently trying to optimize "Efficient Attention at Scale" the entire research is headed on having long-context models use hybrid tricks:
- sparse attention (Tunnel Vision)
- chunked attention (Fragmented Memory)
- memory compression
- retrieval routing
Right now, it appears Google is the only one who has solved this.
If you look at the pricing for Gemini 3 Flash, it does not spike after a certain context threshold. It outperforms competitors like Claude 4.5 Sonnet at 1/5th of the price. This suggests Google has found a way to "pull the line down", likely a proprietary implementation of linear or highly optimized sparse attention that avoids the quadratic cost explosion.
The Optimization Fallacy: A Faster B-Tree for a Graph Problem
Google solving the cost of 1 million tokens is impressive, but it’s an infrastructure fix, not an intelligence fix.
Think of it in terms of database architecture. Large Language Models are essentially massive B-Trees of Probability. They are optimized for Retrieval: finding the "next" token based on sorted, learned patterns, just like a B-Tree efficiently scans for the next record.
Google just built an infinite, ultra-fast cache for this B-Tree. They made the "seek time" effectively zero.
But "Innovation" isn't a Retrieval problem. It’s a Graph Problem.
When you are architecting a novel software system, you aren't scanning for the "next" predictable record. You are solving a dependency graph, traversing disjoint nodes of logic, understanding causality (if I change X, does it break Y?), and deriving a path that doesn't exist in the index.
If you try to use a B-Tree to solve the "Traveling Salesman Problem," it doesn't matter how fast your disk seek is or how much RAM you have. The data structure itself is wrong. You are optimizing the lookup of the average path, when the problem requires computing a novel one.
We have optimized the latency of the look-up, but we haven't fixed the logic of the traversal.
Addressing the nuances
- "LLMs are B-Trees" don't take this literally because:
- B-Trees: Discrete keys, O(log n) lookup, exact retrieval
- LLMs: Continuous embeddings, O(1) per token, probabilistic
- Better analogy: "k-NN in embedding space" or "lossy compressor"
- "Innovation is a Graph Problem, not Retrieval" is oversimplified:
- LLMs DO perform graph-like computation (attention is a fully-connected graph)
- The real limitation: No backtracking, no systematic search, no constraint satisfaction
- Better framing: "Heuristic search vs Systematic search"
I don't want to go technical for a general understanding for all readers but nuances needs to be addressed
What Can't Be Fixed with Speed:
Even with 0-cost inference, LLMs fundamentally cannot:
- Backtrack systematically (Sudoku solving)
- Perform exhaustive search (prime factorization)
- Guarantee exact computation (arithmetic)
- Maintain global constraints (long-range dependencies)
- Do causal counterfactuals ("if X changed, what breaks?")
This is because LLMs are derived fundamentally from Neural Networks, which are Universal Functional Approximators.
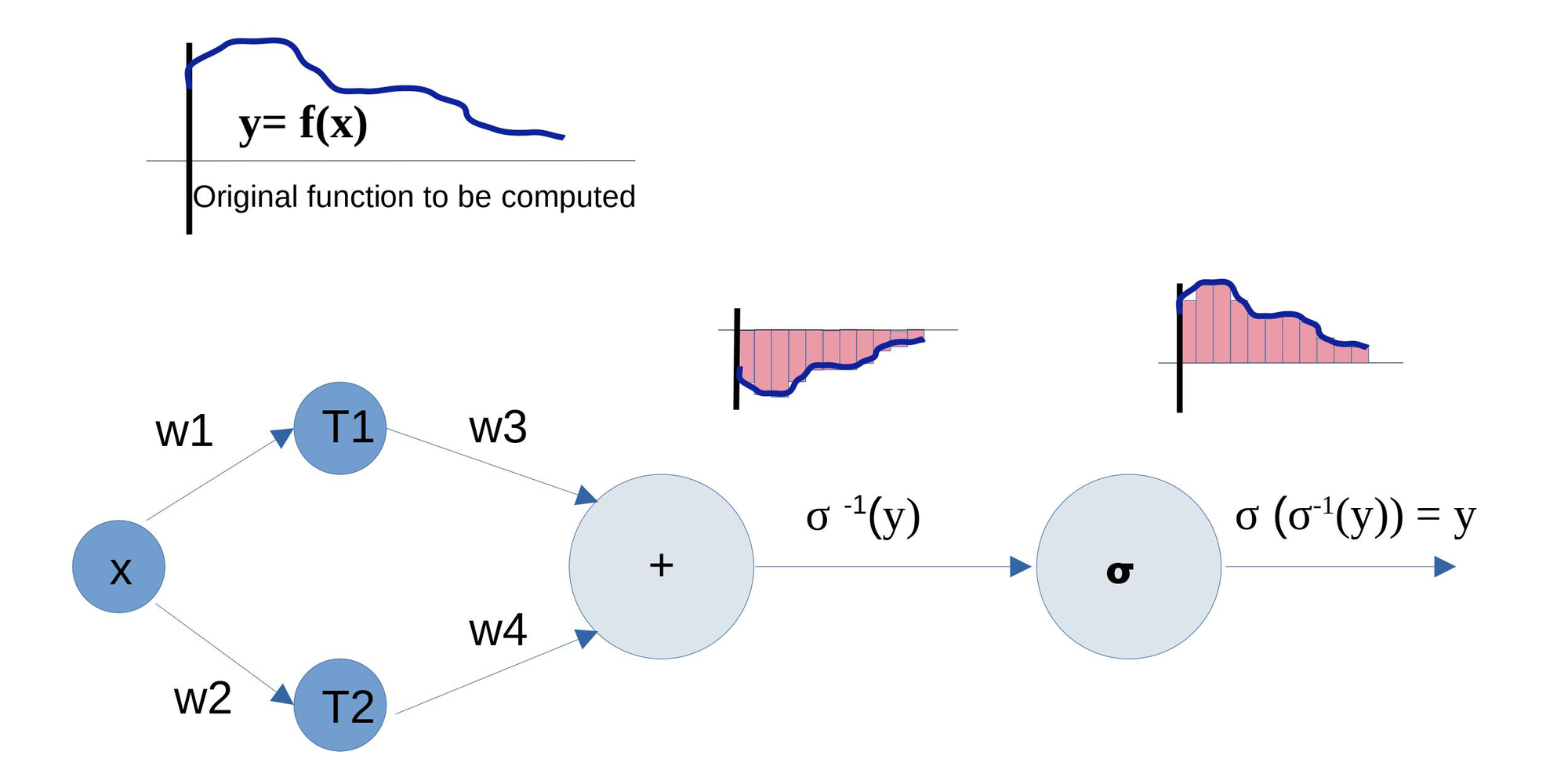
There's a great paper on Universality of Deep Convolutional Neural Networks
This is a mathematical method called "Curve Fitting." It can approximate the shape of a function perfectly, but it does not know the formula of the function.
Are Humans Just Approximators Too?
You might ask: "Aren't we just biological neural networks? Don't we approximate too?"
NO! Most of the time, we are approximators. When you drive a car or catch a ball, you are using "System 1" thinking fast, intuitive approximation. You are curve-fitting.
But humans have a something that LLMs lack
We can switch to "System 2" thinking. We can stop approximating and start Deriving. We can perform exact logic, step-by-step verification, and first-principles reasoning that is completely detached from our training data (memory).
This ability to switch modes is what creates our Statistical Leverage. Think of it? we did not learned from millions and billions of examples, infant a few is sufficient.
Human's Statistical Leverage
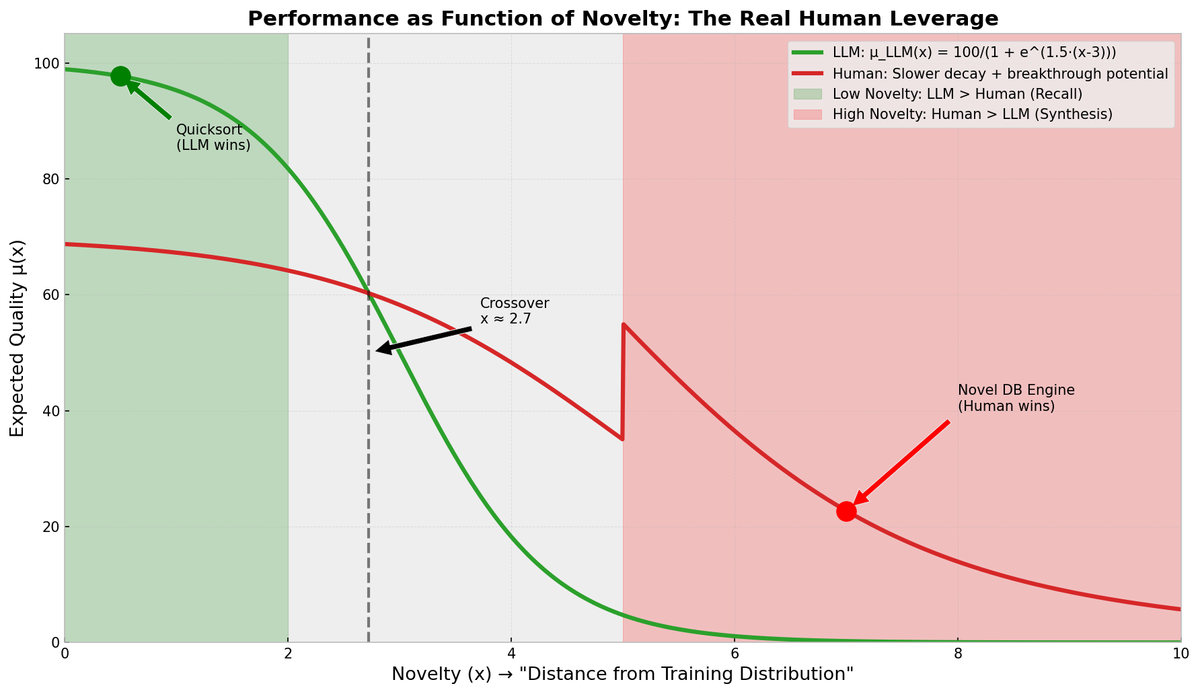
Let Q be a scalar measure of output quality (higher = better). Model an LLM output as a random draw:
For a high quality threshold T (breakthrough):
Because Pareto tails decay polynomially, for sufficiently large T we often have:
Even if μL ≥ μH. That inequality formalizes human leverage: humans have a larger probability of producing extreme positive outliers (breakthroughs).
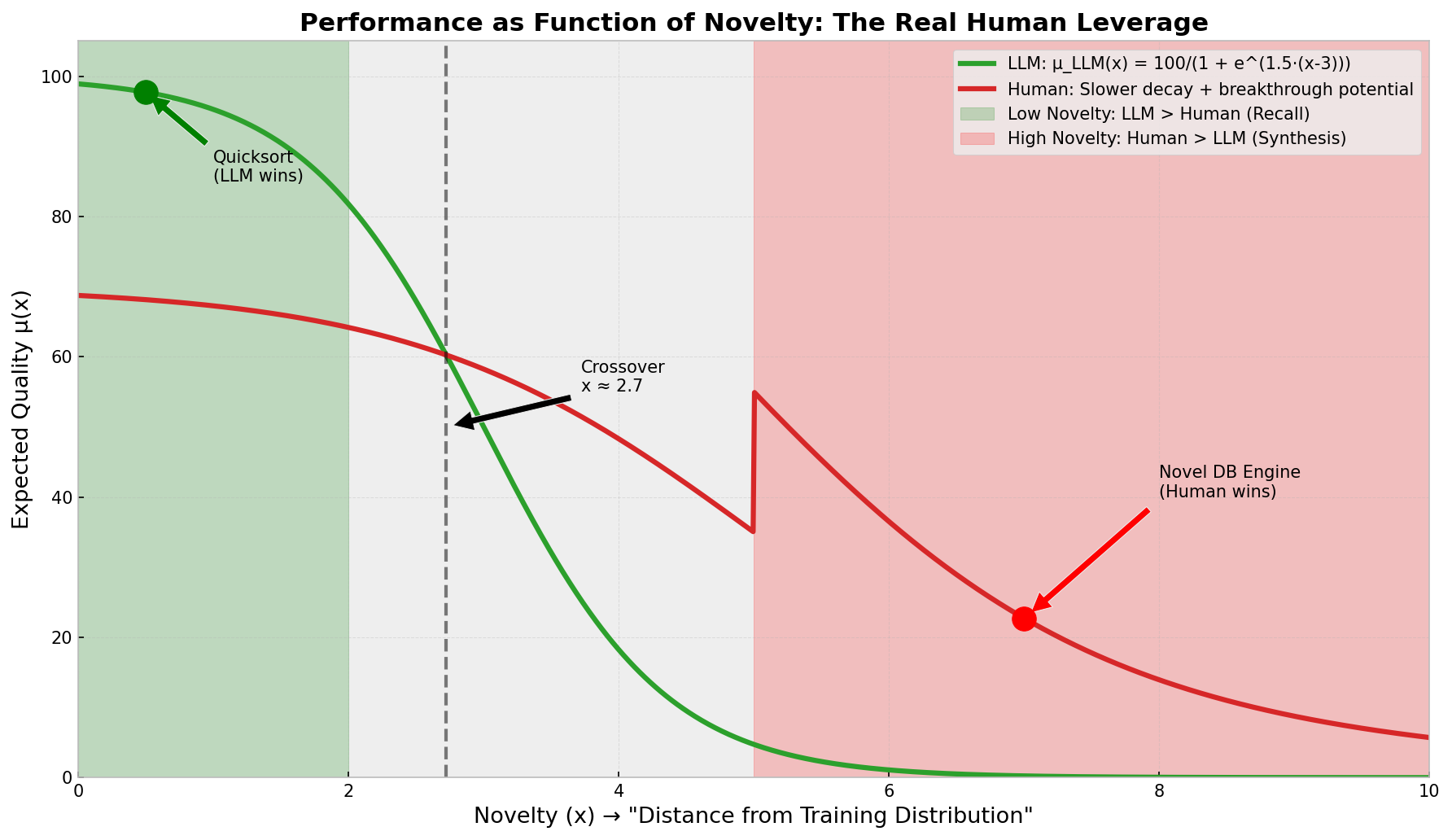
This is an output of the chart from this script i wrote in python to visualize the leverage
Conclusion
LLMs, by design, will fundamentally fail to discover breakthroughs since they converge toward the statistical mean. The correct way to use them at the enterprise level is only feasible by throwing massive amounts of compute at the problem, like Google’s DeepMind projects, which is extremely inefficient compared to hiring expert humans.
For LLMs to produce something meaningful, we must first solve how to measure the quality of the output, since it becomes humanly impossible to find novelty in AI slop, benchmarks can reveal heuristics but cannot measure individual outputs. If everything in this current architecture is solved in the next 10 years, we will commoditize AI that can produce average solutions that are already built or where similar solutions exist.
What does this mean for SaaS?
Is coding dead? No.
LLMs or similar methods are inefficient for solving enterprise-level or scale problems that require breakthroughs, like Uber did with its H3 algorithm or the LMAX Disruptor used by high-frequency trading firms.
In general, to solve "scale problems" or "low-latency/high-throughput systems", you still need deep engineering. Anyone will be able to make a basic CRUD application, which honestly was not software engineering anyway; people can already do this themselves, and there are many open-source repos for SaaS apps like CRMs or document processors.
SMEs relying only on AI based solutions for quick wins will fundamentally fail once they hit scale problems and will need enterprise-grade solutions
companies like Microsoft are going to leverage that. It is going to be cheaper for SMEs to build average or generic solutions, but once they hit scale! they will need enterprise solutions.
Zoho & ManageEngine should get 110% enterprise-ready and handle scale, latency, throughput. It is in a uniquely strong position to own the entire infra and code-to-service stack.
AI increases productivity and SME to Enterprise transition will be much quicker, focusing on getting those customer is the key as people its hard to switch enterprise solutions once their workflow is embedded into a vendor ecosystem (vendor lock-in)
It will soon be the era of companies that have highly sophisticated software like Databricks, Snowflake, ManageEngine, Palantir, Stripe, NVIDIA, AWS, Google Cloud, Cloudflare, Confluent, Elastic, and SAP.
Wrapper products will simply not work!
Is graphic design or content writing dead?
If you are just following a design pattern like Material Design and applying guidelines, then yes. But real graphic design is about understanding psychology. Someone built Material Design for Android, Liquid Glass, or Windows UI; changing these fundamental principles to come up with something new is something AI is unlikely (probabilistically) to do. True creativity does not die. Only the automation of learning principles and applying them will be approximated by neural network approximators, whether LLMs or CNNs.
The same goes for content writing. Simple copy-pasting, aggregation of sources, and similar tasks are dead. LLMs are very efficient at these, even without deep context. But I am also writing content. The reason you are reading it is because LLMs cannot fully replicate the unlimited context and insights I possess. Insights, similar to breakthroughs, are what I can consistently produce, while LLMs might have a one-in-a-million (without context) chance to generate something that truly blows people’s minds and is factually grounded.
If you stay average, these function approximators will overshadow you. But if you keep pushing yourself and keep learning, you can beat the odds and create better things, in code or in art. Treat them as a short-term nitro boost; over the long run, the driver wins the race, not the nitro boost system.
What about Video editing and Content creation?
AI will dominate mechanical editing, stock-style motion graphics, and bulk content generation. It will be very efficient at repackaging existing formats and optimizing for engagement heuristics. But breakthrough formats, strong editorial judgment, and consistent creative direction remain scarce.
Reel Composer - AI automation video creator (made me 22K followers on Instagram)
Someone originally defined the grammar of jump cuts, retention editing, short-form hooks, and platform-native storytelling; shifting those fundamentals or creating new ones is still a human-driven process.
Editing will be solved, good content will become the scarcity
The First Mover Leverage
First-mover leverage still dominates. (It is gonna come mostly from the human side) Microsoft leads enterprise SaaS because early adoption let it embed into workflows and lock in distribution before competitors caught up. The same applies to video and content. The first creator or company to crack a new problem or a new format gains distribution, audience habit, and platform reinforcement. By the time AI replicates the mechanics, there is a delay, and that delay lets the first mover compound reach, data, and brand. Once adoption is ingrained, they dominate.
This is just R&D economics. Breakthroughs capture the high-margin position, then followers scale. AI will mainly wipe out cheap copycats and wrapper SMEs because volume and optimization can be automated. The dominant second player after a breakthrough will be large organizations using AI at scale with strong distribution, not small imitators. First movers set the paradigm, and AI-powered incumbents absorb the commoditized layer.